It's late, and I can't sleep, so I thought I'd write about the area I'm developing in:
TTS
(in this context, I prefer to call "the conversational AI audio pipeline" simply "tts")
Why read this? Because I've been staying up late into the night for the past 2 months obsessing over this side project I'm working on and I've gotten to know the tts realm pretty well! Oh also, I promise this is 100% human written (Even the diagrams!!!). Hopefully you value that (or hopefully you can tell it's human-written?).
This is my first post. Here goes.
You've probably heard that you can't get something that is all of: fast, cheap, and high-quality. But I think we're actually headed in that direction with tts (until us humans move the goal post).
Let me give you a lay of the land; the current tradeoffs one must make with tts starting... well... at the start!
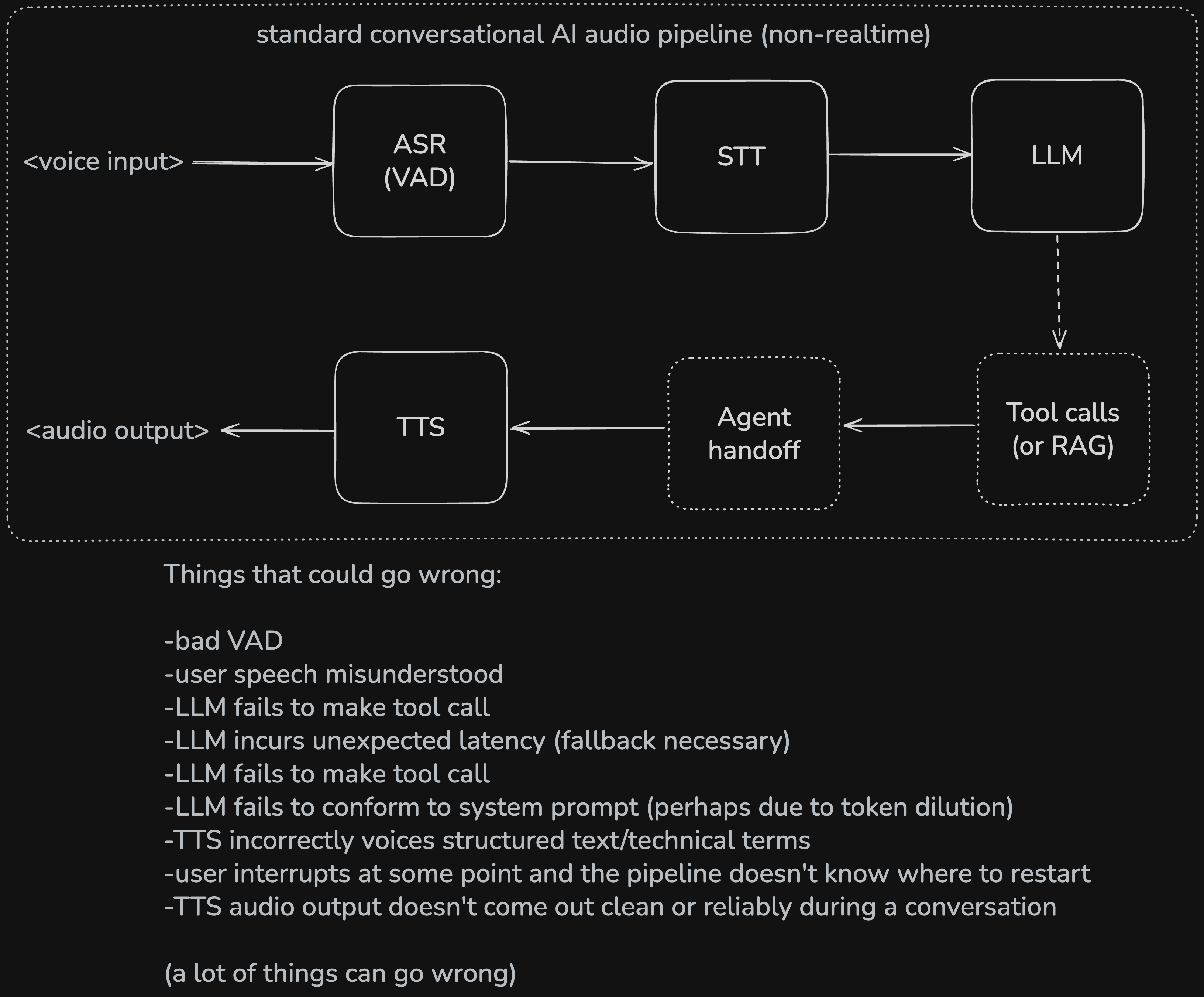
User voice in →
Here we must use VAD (voice activity detection, some people call this ASR, "automated speech recognition"). I heard that last year, 250m hours of audio was sent to Assembly AI, which is very hard to believe. But anyway, they're special because they have what's called semantic VAD. They don't just listen for when you stop talking, they consider the tokens you've spoken thus far to determine if you REALLY finished your turn.
Plain VAD pales in comparison to this. As humans, obviously we don't wait for an n-millisecond pause before deciding to start formulating a reply.
To me, smart VAD is table stakes. Think about the mock Investment Banking interview tool out there right now. I should be able to hum, hah, and pause in thought on how the three financials statements flow together or whether or not acquiring a company with a specific P/E compared to mine is accretive or dilutive. If the model starts speaking back when I pause, it's ruined. Illusion, ruined.
Speaking of VAD: here's a little VAD wishlist, i.e., my dream VAD: low latency, semantically decides if you're done taking your turn, only listens for your voice, and properly filters out background voices. Oh and for some use cases, it'd be cool if VAD only triggers on primary user's voice, after a one-time voice fingerprint at sign-up. Huge advancements are being made in VAD (That YT video was posted 9 days ago!!).
Here's something a bit nerdy about turn detection (smart VAD): it really only makes sense to run a turn detection model locally, so most of the innovation happening around turn detection is pushing down model size.
You might be asking why it only makes sense to run locally. It's because usually input audio is chunked into very short frames (10-40ms). But let's say we chunk at 100ms intervals. For a 5s utterance, that's 50 inferences per utterance. I don't want to pay that network overhead. Today, a multilingual turn detection model running locally requires about 400MB of ram, and is about 396MB on disk and completes inference in about 25ms ("modest system requirements"). You'd have to include that in your app package size. Quantized versions can be like 88MB, but you of course lose accuracy.
Speaking of accuracy, here's today's end of turn detection accuracy across a bunch of languages using the tiny Qwen2.5-0.5B-Instruct model (~50-160ms per turn latency, but perhaps it's worth it.)
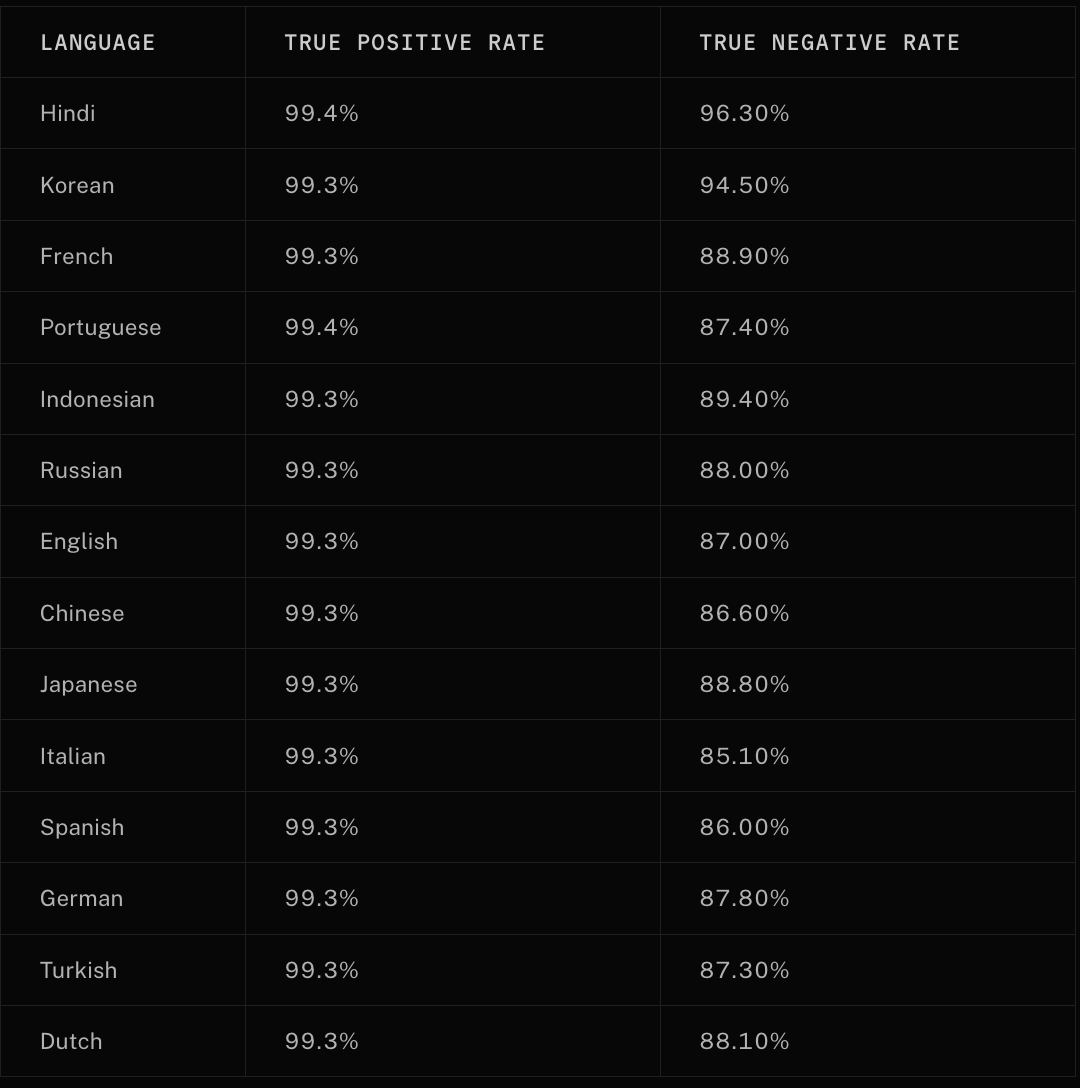
^^ from livekit (Interestingly, English is super low for True Negative rate, above only spanish and italian. Perhaps there's a linguistics explanation for this? Also, why is True Positive rate so tight and much higher than true negative? Super interesting.)
"Hey siri, set a 10 minute timer!" "siri!" "SIRI! SET A 10 MINUTE TIMER!"... later that day in random conversation: "are you serious?", *siri activates*. I will say Apple's job is hard because they must be "always listening" for that keyword, and if they listen too closely, it's either annoying or encroaching. "Woah, I was just talking about lizards with my friend and now I'm getting ads for reptile terraria!"
Next node: speech-to-text!
STT is the most boring but most important node in the audio pipeline. Why? Maybe it's just me, but if I accidentally hit enter prematurely when I'm writing a prompt to Perplexity, I cancel that llm reply so fast. It's weird to admit but it's almost like I'm embarrassed that I wrote "what" and the LLM proceeds to do a most earnest job at responding to "what", when I really meant "what would it take to build a crawler like googlebot?" . Multiply that by 10 when speaking with an AI that your brain has been tricked into thinking is a real human.
Have you ever accidentally stepped on your dog's foot and start apologizing profusely in hopes that your dog can understand it was an accident? But you can't? An immutable chat history with a realtime LLM is basically this same sitch
So either fix yo STT, or make it really easy for the user to retract what they just said. The latter is easier said than done (smoothly)...
Now we arrive at TTS!
^^ from livekit, list of all ready-made TTS "plugins". Wow, that's a big list. "Spitch" is, of course, the best name for a tts plugin.
Here's a laundry list of features that currently exist, and factors one must consider when selecting a tts provider. Keep in mind that no one single provider has all of these features, and you must make tough tradeoffs when selecting one.
- Usage of enhance tags, like [LAUGHS], [SIGHS], [PAUSES]. Try inserting [WHISPERS] into an input sentence on Elevenlabs' v3 model, it's really neat. Most providers don't have this capability.
- Paragraph/sentence/response-level prompts: "speak the following very very calmly" <-- this importantly uses the same underlying voice. With Gemini you can control tone, accent, style, pace. Not sure why you would want to control accent...
- Voice gen via prompt. This is an interesting one. I would think it's much more common do it like the following:
- Via example audio file. I uploaded 10 minutes of extremely crisp audio, and Elevenlabs gave me junk. Point is, if we don't have good voice gen via audio input today, we're pretty far off from voice gen via text prompt.
- Pauses for n seconds, where n can be however long you want. For some reason the max pause on Elevenlabs is like 3.5 seconds?? This is more of a luxury laundry list item, I can manage my own pauses in code.
- Special pronunciations! Providing a list of keywords and their pronunciations so the tts knows how to say them: for example, I specify a mapping that contains things like "EV/EBITDA":"E V to e-bit-dah". Only some providers allow SSML (speech synthesis markup language), and for those that do, it only works on certain models/versions. It's a formal way to specify pronunciation, and you can do a few other things in SSML too. Example:
<phoneme alphabet="ipa" ph="ˈæktʃuəli">
actually
</phoneme> - Latency! Today, providing response-level special prompts introduces, like, 10s of latency for 100 tokens. That's not gonna work.
- Smartly not reading numbers (hint, I can do this in code) or reading numbers smartly! No, not "three hundred and eighty five", that's my phone number, "three eight five ...". What about more complex output? (hint hint, I can do this in code). Elevenlabs just released an update that improves the accuracy of certain categories of structured output to be spoken correctly. On another note, my wife sent me a message with four emojis at the end, like this: 😵💫😵💫😵💫😵💫. Siri proceeded to say "face with spiral eyes and wavy mouth" over and over. Strange.
- Cost. Is Elevenlabs paying real professional voice actors to voice my output? For the Scale tier, you only get 2m tokens spoken. That's right, 2m. I turned on MAX mode on sonnet-4.5-thinking in cursor, gave it a trivial .yaml CI file to fix, and 2 mins later I apparently used 63,000 tokens. Luckily I received back a still-broken .yaml. Scale tier is $330/month!
- Sound quality output: I've tried Agora, Assembly, Livekit, etc., one of these companies has a demo basically on the front page you can go try. It sounds like you're on the phone with your grandmother on the other side of the planet. Not only do I need high quality sound, I need it to be consistent.
- Creativity/stability modulation: This one is crazy. There's literally a slider you adjust and it modulates how "creative" or exaggerated/expressive the output is.
- Speed of speech. This one is pretty trivial and all TTS providers should implement it.
So that's TTS. It has the most levers, and it's the most fun of the audio nodes. To wrap up, let's visit the following:
What would my dream TTS provider look like? It needs a few things:
- It must be super low latency.
- The voice must sound the same whether the user connects on phone or laptop.
- I can provide it a list of key terms with special pronunciations, without needing SSML.
- I can give prompt-level instructions like “say this next bit as if you're fighting for your life.”
- I can use enhance tags anywhere I want.
- I get amazing results when I clone a professional voice.
Anyway, thanks for reading.
Let's hope I can go to bed now.
Leave me a note at i16n [@] wallacecorp [dot] ai if you're interested in what I'm building, building in a similar area, or just want to shoot me an email regarding this post. I love feedback, so please do!
Au revoir! Til next time.
===============================